



In the realm of artificial intelligence, one innovation has dramatically changed how we interact with machines using natural language: Generative Pretrained Transformers (GPT). Developed by OpenAI, GPT represents a family of models built on the principles of deep learning, specifically tailored for Natural Language Processing (NLP). Its impact is extensive, and now covers all major industries and even our personal lives. Can you imagine your work without ChatGPT? Probably not!
The generative pre-trained transformer market is also one of the fastest-growing sectors in the world. According to a Statista report, the global GPT market is expected to be $356.10bn in 2030.
But what is a generative pre-trained transformer and how does it work? How does it impact the different areas of our lives and how can we utilize it? These are the main questions that most of us have in our minds. And that’s what we are going to answer in this blog. So, without any further ado let’s get right into it.
What Is A Generative Pre-trained Transformer?
GPT models are designed to generate coherent and contextually relevant text based on a given prompt. They leverage a type of deep learning architecture known as transformers to process and understand the complex patterns inherent in human language. They are basically, a neural network architecture that brought significant improvements over older models like RNNs and LSTMs.
The concept of “pretraining” is crucial here. GPT models are first trained on vast datasets, allowing them to learn the intricacies of language. This pretraining equips the models with a general understanding of linguistic structures, which can then be fine-tuned for specific tasks.
How GPT Works: The Transformer Architecture
The power of enterprise GPT lies in the revolutionary transformer architecture. Before transformers, traditional models like Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs) dominated NLP tasks. However, these architectures had limitations in processing long sequences of text, particularly when it came to capturing dependencies between distant words in a sentence.
Self-Attention Mechanism
Transformers address these limitations through a mechanism known as self-attention. In GPT, self-attention allows each word in a sequence to consider every other word, thereby creating a context-aware representation of the text. This is achieved using attention heads, each focusing on different parts of the sentence. For instance, in the sentence “The cat sat on the mat,” the self-attention mechanism helps the model understand that “sat” is closely associated with “cat” rather than “mat.”
This allows the model to focus on relevant parts of the input when generating predictions.
Self-attention is defined by: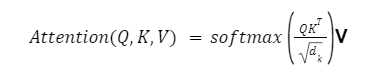
Where:
Q = Queries
K = Keys
V = Values
d_k = Dimension of key vectors
Multi-Head Attention
GPT also employs multi-head attention, a process where multiple attention mechanisms work in parallel to capture different aspects of the input sequence. Each head operates independently, focusing on different parts of the sentence, and their outputs are combined for richer representations.
Encoder-Decoder Structure
While the original transformer model has an encoder-decoder structure, GPT simplifies this by using only the decoder part for text generation. The encoder is primarily used for input processing (as in models like BERT), whereas GPT, being generative, focuses on predicting the next word in a sequence.
Backpropagation and Training
GPT is trained using backpropagation, where gradients are computed for each weight in the network, and the model’s parameters are adjusted using an optimization algorithm (usually Adam). This process is repeated over multiple epochs to minimize the difference between the predicted and actual outputs, ultimately improving the model’s performance.
Training large-scale models like GPT requires vast computational resources, and parallelization techniques are often employed to speed up training. Distributed training across multiple GPUs or TPUs is a common approach, enabling the model to handle the immense number of parameters.
Evolution of Generative PreTrained Transformers (GPT-1 to GPT-4)
The evolution of generative pre-trained transformers from simple chatbots to enterprise AI has been nothing short of extraordinary. Here’s a glimpse:
GPT-1: The Beginning of Generative Pretraining
GPT-1 was introduced in 2018 with 117 million parameters. It was the first model to demonstrate that generative pretraining on large amounts of unlabeled text followed by fine-tuning on smaller, labeled datasets could produce high-quality results on various NLP tasks. GPT-1 established the foundation for transfer learning in NLP, leveraging unsupervised learning to build strong language representations.
| Model | Parameters | Notable Features |
| GPT-1 | 117M | Introduction of generative pretraining |
GPT-2: Scaling Up
Released in 2019, GPT-2 scaled up the model to 1.5 billion parameters. Its increased size allowed it to generate even more coherent and contextually relevant text. GPT-2 also introduced concerns about potential misuse, leading OpenAI to initially withhold the full model. However, its public release sparked widespread adoption and further highlighted the potential of large-scale language models.
| Model | Parameters | Notable Features |
| GPT-2 | 1.5B | Capable of generating realistic text |
GPT-3: A Quantum Leap
GPT-3 (2020) was a game-changer, with 175 billion parameters. GPT-3 showed remarkable improvements in few-shot, one-shot, and zero-shot learning, allowing it to perform tasks with minimal examples. Its ability to understand and generate language across a wide range of tasks without specific task-related fine-tuning made it a landmark achievement in AI.
| Model | Parameters | Notable Features |
| GPT-3 | 175B | Few-shot learning, robust text generation |
GPT-4: Pushing the Boundaries
GPT-4 (2023) continued the trend of scaling with more refined models and increased data. While OpenAI has not disclosed the exact number of parameters, GPT-4 is widely acknowledged for improved multimodal capabilities (e.g., image and text), enhanced coherence, and better alignment with human values and ethical considerations.
| Model | Parameters | Notable Features |
| GPT-4 | Confidential | Improved multimodal capabilitie |
Pretraining and Fine-Tuning in GPT
Pretraining: The Foundation of GPT
Pretraining is a crucial phase in the development of Generative Pretrained Transformers (GPT). It involves training the model on vast amounts of unlabeled text data to understand the underlying structure and patterns of language. This stage is completely unsupervised, meaning that the model is exposed to raw text and learns to predict the next word in a sentence by examining the context provided by the preceding words. The model does not need labels or explicit task-specific data during this phase, making it incredibly efficient at generalizing across a wide range of NLP tasks.
During pretraining, GPT learns relationships between words, sentence structures, and even deeper linguistic features such as idiomatic expressions and nuances in meaning. This is achieved through masked language modeling—a technique where the model is tasked with predicting missing words in a sentence. Over time, GPT develops a rich representation of language, capturing syntactic, semantic, and contextual information.
Pretraining involves several key components:
Tokenization: Text is broken down into tokens (words, subwords, or characters). GPT typically uses byte pair encoding (BPE) to tokenize text, enabling it to handle words it has never seen before.
Objective Function: The model is trained to minimize a cross-entropy loss function, where it learns to predict the probability distribution of the next word in a sequence given its context.
Optimization: Pretraining requires massive computational resources, typically running on high-performance hardware (e.g., GPUs, TPUs). The Adam optimizer and gradient descent are used to adjust the model’s parameters, ensuring it can learn from its errors and improve over time.
Learning Dynamics: The model undergoes multiple epochs (complete passes through the training dataset). Early epochs capture basic language rules, while later epochs refine the model’s understanding of context and meaning.
An important aspect of pretraining is that it can leverage diverse datasets from the internet, such as Common Crawl, Wikipedia, and digital libraries. This vast exposure allows GPT to develop a wide-ranging understanding of language, including rare words, technical jargon, and various languages.








