Delta Lake on Microsoft Fabric: Get Started Fast
Delta Lake on Microsoft Fabric is delta Lake works in Microsoft Fabric, why it matters for lakehouse architecture, and how to start with ACID tables, medallion design, Direct Lake, and production-ready analytics patterns.
Learn how Delta Lake works in Microsoft Fabric, why it matters for lakehouse architecture, and how to start with ACID tables, medallion design, Direct Lake, and production-ready analytics patterns.
Al Rafay Consulting
· Updated June 8, 2026 · ARC Team

If your organization is adopting Microsoft Fabric, you need to understand one of its most important foundations: Delta Lake. It is not just a file format detail. Delta Lake is what turns raw lake storage into a reliable, transactional, analytics-ready data layer.
In Fabric, Delta tables are central to how lakehouse workloads operate. They support ACID transactions, time travel, scalable reads, structured pipelines, and shared access patterns across Spark, SQL analytics endpoints, and Power BI.
This matters because lakehouse success is rarely about storing more files. It is about making data usable, trustworthy, and fast enough for engineering and reporting teams to share the same foundation.
Why Delta Lake Matters in Microsoft Fabric
Fabric is built around OneLake, but OneLake alone is not enough. Data teams still need a table format that supports reliability, consistency, and efficient analytics workloads. Delta Lake provides that layer.
With Delta Lake in Fabric, teams get:
- ACID transactions for more dependable data updates
- Schema enforcement and better pipeline quality control
- Time travel for rollback, validation, and audit needs
- Open-format interoperability with modern data workloads
- A strong fit for bronze, silver, and gold lakehouse patterns
Instead of treating the lake as a loosely organized file dump, Delta Lake helps make it an operational analytics platform.
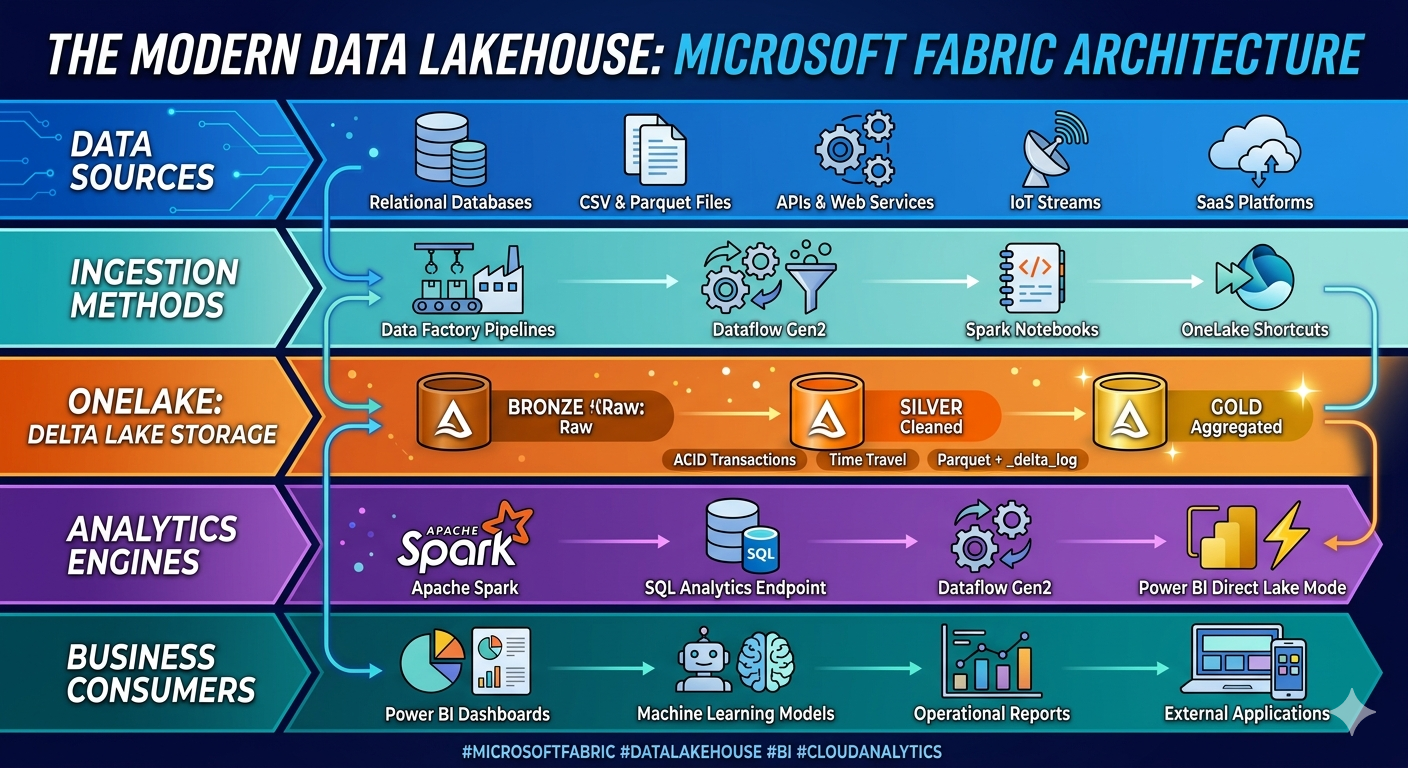
Delta Lake and the Fabric Lakehouse Model
In Fabric, a lakehouse gives teams a place to land files, create Delta tables, run Spark jobs, expose SQL endpoints, and support downstream BI without forcing separate warehouse and lake designs from day one.
Lakehouse vs. Warehouse in Fabric
The question is not which one is universally better. It is which access pattern your workload needs.
- Use a lakehouse when you need engineering flexibility, raw-to-curated data pipelines, Spark-first workflows, or mixed file and table patterns.
- Use a warehouse when you need strongly modeled SQL analytics patterns, dimensional design, and warehouse-centric query behavior.
Many Fabric environments use both. Delta Lake often becomes the shared storage and transformation layer that feeds business-friendly models downstream.
Why Delta Tables Are the Default Choice
Delta tables give Fabric teams a more production-ready storage pattern than plain parquet folders. You gain version tracking, transaction logs, improved reliability, and better support for incremental engineering patterns.
Core Delta Lake Capabilities You Should Use Early
| Capability | Why It Matters | Practical Value |
|---|---|---|
| ACID transactions | Prevents partial writes and inconsistent table state | More reliable pipelines |
| Time travel | Query earlier table versions | Easier validation and rollback |
| Schema enforcement | Protects table quality as sources evolve | Fewer silent data issues |
| MERGE support | Handles CDC and upserts cleanly | Better incremental loading |
| Performance optimizations | Improves read efficiency for analytics | Faster downstream reporting |
The source material also highlights V-Order and Fabric-specific optimization patterns that improve compression and read performance for analytical workloads.
A Practical Delta Lake Roadmap in Fabric
The fastest way to get value is to avoid over-design and focus on a clean data flow.
| Step | Focus | Outcome |
|---|---|---|
| Step 1: Land source data | Ingest files, app data, or streaming feeds into OneLake | Reliable raw landing zone |
| Step 2: Create Delta bronze and silver layers | Standardize quality, schema, and transformation logic | Cleaner shared datasets |
| Step 3: Publish gold data products | Shape business-ready tables and semantic outputs | Faster reporting and reuse |
| Step 4: Expose analytics endpoints | Support SQL analytics and Direct Lake reporting | Low-latency consumption |
Step 1: Land Source Data in OneLake
Use Data Factory pipelines, shortcuts, notebooks, or streaming inputs to land data in a governed location. Keep the raw layer stable and auditable.
Step 2: Standardize with Bronze and Silver Layers
Use notebooks or pipelines to cleanse data, enforce schema, and apply reusable transformation logic. This is where Delta Lake starts creating operational reliability instead of just storing files.
Step 3: Publish Gold Data Products
Gold-layer tables should exist for a reason: reusable reporting, executive metrics, governed domain outputs, or machine learning features. Avoid creating too many “almost final” layers with unclear ownership.
Step 4: Expose the Right Consumption Pattern
Fabric makes it easier to connect Delta-backed data products to SQL analytics endpoints, Power BI, and Direct Lake scenarios. This shortens the path from engineering to business consumption.
Where Delta Lake Fits Best in Real Use Cases
Delta Lake on Fabric is especially strong in scenarios where incremental change, auditability, and cross-workload reuse matter.
- BI and executive reporting: Curated gold tables can feed Direct Lake and Power BI with lower latency.
- IoT and streaming analytics: Continuous ingestion benefits from append-friendly, scalable table patterns.
- CDC and operational sync: MERGE support makes incremental upserts more manageable.
- Machine learning feature pipelines: Standardized Delta layers create more reproducible feature engineering.
- Compliance and audit workloads: Time travel and clear versioning help with validation and traceability.
Common Mistakes When Starting with Delta in Fabric
- Treating the lakehouse as an ungoverned file store
- Skipping bronze, silver, and gold ownership rules
- Building gold outputs before schema quality is stable
- Ignoring small-file and optimization considerations
- Using warehouse-only design assumptions for every workload
Teams move faster when they establish a few opinionated standards early: ingestion conventions, table naming, refresh patterns, retention rules, and ownership boundaries.
Business Value of Delta Lake on Fabric
- More reliable pipelines through ACID-backed updates
- Better performance for mixed engineering and reporting workloads
- Faster debugging and rollback through time travel
- Stronger reuse across Spark, SQL, and Power BI consumption patterns
- Cleaner modernization path for lakehouse-first analytics strategies
Frequently Asked Questions
What is Delta Lake in Microsoft Fabric?
Delta Lake is the transactional table layer used in Fabric lakehouse workloads. It adds ACID transactions, schema enforcement, time travel, and scalable table behavior on top of open storage formats, making OneLake data more reliable for engineering and analytics.
When should I use a Fabric lakehouse instead of a warehouse?
Use a lakehouse when your workload depends on raw-to-curated engineering, Spark processing, or flexible file-plus-table patterns. Use a warehouse when you need more structured SQL-centric modeling. In many Fabric environments, both coexist, with Delta-backed lakehouse layers feeding downstream warehouse and BI use cases.
Why is time travel useful in Delta Lake?
Time travel allows teams to query earlier versions of a Delta table. That is valuable for debugging, validation, audit review, rollback scenarios, and investigating when a transformation introduced an issue.
How does Delta Lake support Power BI and Direct Lake scenarios?
By organizing data into performant, governed Delta tables, Fabric makes it easier to expose curated datasets to SQL endpoints and Power BI. Direct Lake scenarios benefit when the underlying Delta-backed data products are clean, stable, and shaped for consumption.
Conclusion
Delta Lake is one of the reasons Microsoft Fabric can support a real lakehouse operating model instead of just a new storage layer. It gives teams the reliability, performance, and structure needed to turn raw data into trusted products for analytics and AI.
If your organization is building a Fabric lakehouse, ARC can help with architecture, medallion standards, Direct Lake strategy, and production-ready engineering patterns.
Frequently Asked Questions
What is Microsoft Fabric?
How is Fabric different from Azure Synapse?
What is OneLake in Microsoft Fabric?
How does Fabric pricing work?
Can I use Fabric with existing Power BI reports?
Al Rafay Consulting
ARC Team
AI-powered Microsoft Solutions Partner delivering enterprise solutions on Azure, SharePoint, and Microsoft 365.
LinkedIn Profile